让大模型训练更高效,奇异摩尔用互联创新方案定义下一代AI计算

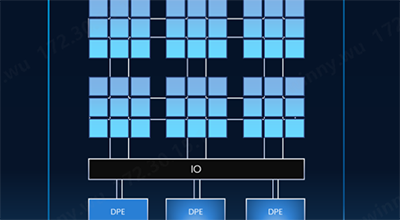
近一段时间以来,DeepSeek现象级爆火引发产业对大规模数据中心建设的思考和争议。在训练端,DeepSeek以开源模型通过算法优化(如稀疏计算、动态架构)降低了训练成本,使得企业能够以低成本实现高性能AI大模型的训练;在推理端,DeepSeek加速了AI应用从训练向推理阶段的迁移。
近一段时间以来,DeepSeek现象级爆火引发产业对大规模数据中心建设的思考和争议。在训练端,DeepSeek以开源模型通过算法优化(如稀疏计算、动态架构)降低了训练成本,使得企业能够以低成本实现高性能AI大模型的训练;在推理端,DeepSeek加速了AI应用从训练向推理阶段的迁移。

8月1日,arm 服务器 CPU 供应商Ampere Computing 放了一个大招,发布了一款有512 个内核的人工智能处理器AmpereOne Aurora。


人工智能芯片研发及基础算力平台公司爱芯元智宣布,以“开放·连接”为主题的第二届玄铁RISC-V生态大会于03月14日在深圳举行,爱芯元智联合创始人、副总裁刘建伟受邀发表主题演讲,向与会嘉宾分享了爱芯通元混合精度NPU这一面向边端侧算力布局的AI处理器,