
如果说2023年是全球认识生成式AI(GenAI)的开始,那么2024年则是全球各大组织/企业真正探索人工智能商业价值的一年。
随着越来越多用户开始采用生成式AI等人工智能技术,存储等数据基础设施也面临着严峻考验,用户意识到存储需要满足人工智能数据训练与推理对于性能、延时、容量、扩展性等各种严苛需求。
近日,在最新发布的MLPerf AI存储基准评测中,浪潮信息分布式存储平台AS13000G7通过一系列创新技术,显著提升数据处理效率,勇夺8项测试中5项性能最佳成绩,实现集群带宽360GB/s、单节点带宽达120GB/s,在满足AI场景下的高性能存储需求方面展现出卓越能力,为大规模数据处理和AI应用提供坚实基础。
不仅是"容器",还是"加速器"
在传统观念里,存储等数据基础设施就像一个存储数据的"容器";进入到AI时代,在各种AI应用场景中,存储则摇身一变,成为推动AI应用和推动AI产业化的"加速器"。
以此次MLPerf测试为例,通过运行一个分布式AI训练测试程序,模拟GPU计算过程,要求在GPU利用率高达90%或70%的条件下,以存储带宽和支持的模拟 GPU (模拟加速器)数量为关键性能指标,来评估AI训练场景下存储的性能表现,从而验证存储对GPU算力的加速能力。
如果把计算节点比作"数据工厂",存储介质则相当于数据仓库。提升存储性能,意味着用户能够在同一时间内通过"存储高速"在"数据工厂"和"数据仓库"之间更高效地存取"数据物料"。
例如,人工智能的大模型训练数据加载、PB级检查点断点续训(其中,检查点相关开销平均可占训练总时间的12%,甚至高达43%)和高并发推理问答等场景下,存储系统的性能直接关乎整个训练与推理过程中GPU的有效利用率。尤其是在万卡集群规模下,相当于规模庞大"数据工厂","生产机器"GPU一旦开动,如果没有及时输送"数据物料",约等于让GPU闲置。有数据显示,存储系统1小时的开销,在千卡集群中就意味着将浪费1000卡时,造成计算资源的损失和业务成本剧增。
那么,要实现"数据物料"的快速高效运输,可以从存储哪些方向入手?
其一,减少中转站--数控分离。通过软件层面的创新,将控制面(数据工厂)和数据面(介质仓库)分离,减少数据中转,缩短传输路径,提升存储单节点及集群的整体性能。
其二,增加车道数--硬件升级。硬件层面采用新一代的高性能硬件,通过DDR5和PCIe5.0等,升级存储带宽,增加传输通道数量,提升存储性能的上限。
其三,物料就近存储--软硬协同。在软硬协同层面,基于数控分离架构,自主控制数据页缓存(储备仓)分配策略,灵活调度内核数据移动,数据就近获取,从而实现快速I/O。
接下来,我们将一一介绍这三大性能提升手段背后的实现原理及其主要价值。
软件优化
数控分离,降低80%节点间数据转发量
在传统分布式文件系统中,数据和元数据高度耦合,导致数据读写信息的分发、传输和元数据处理都需要经过主存储节点。在AI应用场景下,随着客户端数量激增和带宽需求扩大,CPU、内存、硬盘和网络I/O的处理能力面临严峻考验。尽管数控一体的分布式文件系统在稳定性方面表现优异,但在面对AI训练等大I/O、高带宽需求时,其性能瓶颈逐渐显现。数据需通过主节点在集群内部进行转发,这不仅占用了大量的CPU、内存、带宽和网络资源,还导致了数据传输的延迟。
为解决该问题,业界曾尝试通过RDMA技术来提升存储带宽。RDMA允许外部设备绕过CPU和操作系统直接访问内存,从而降低了数据传输延迟并减轻了CPU负载,进而提升了网络通信效率。然而,这种方式并未从根本上解决数据中转带来的延迟问题。
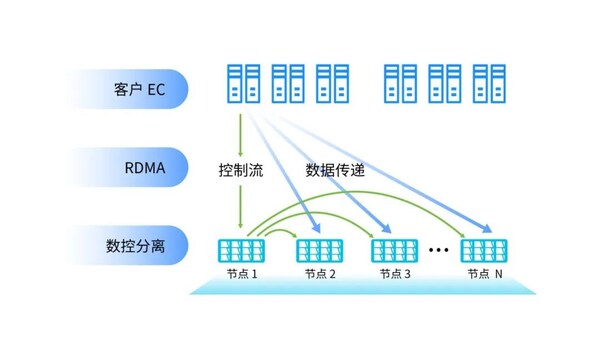
基于此背景,浪潮信息创新自研分布式软件栈,采用全新数控分离架构,将文件系统的数据面和控制面完全解耦。控制面主要负责管理数据的属性信息,如位置、大小等,通过优化逻辑控制和数据管理算法来提高存储系统的访问效率和数据一致性。而数据面则直接负责数据的读写操作,消除中间环节的数据处理延迟,从而缩短"数据物料"的存取时间。
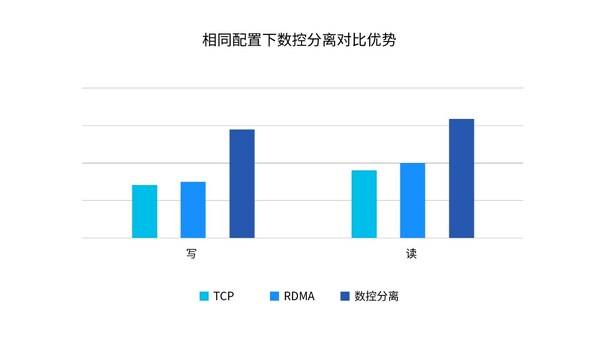
这种数控分离的方式显著减少数据流在节点间的转发次数,降低80%的东西向(节点间)数据转发量,充分发挥硬盘带宽,特别是全闪存储性能。以浪潮信息分布式存储平台AS13000G7为例,在相同配置下,相比于单一TCP和单一RDMA方案,数控分离架构能够带来60%读带宽提升和110%写带宽提升。
硬件升级
拓宽传输通路,实现存储性能翻倍
在AI应用场景下,"数据物料"的快速运输依赖于高效的"存储高速"通道。随着CPU、内存、硬盘等硬件技术的不断创新,升级"存储高速"通道的硬件成为提升存储性能的重要途径。
浪潮信息分布式存储平台AS13000G7采用业界最新高端处理器芯片,如Intel第五代至强可拓展处理器,单颗最大支持60核,支持Intel 最新2.0版本睿频加速技术、超线程技术以及高级矢量拓展指令集512(AVX-512)。同时,支持DDR5内存,如三星、海力士的32G、64G高性能、大容量内存,单根内存在1DPC1情况下,可以支持5600MHz频率,相比与DDR4的3200MHz的内存,性能提升75%。
基于最新处理器的硬件平台,AS13000G7已经支持PCIe5.0标准,并在此基础上支持NVDIA最新的CX7系列400G IB卡及浪潮信息自研PCIe5.0 NVMe。相较于上一代AS13000G6的PCIe4.0的I/O带宽,实现带宽提升100%。
在设计上,G7一代硬件平台将硬件模块化设计理念最大化,将处理器的I/O全部扇出,采用线缆、转接卡等标准设计,实现配置的灵活性。最大可支持4张PCIe5.0 X16的FHHL卡,所有后端的SSD设备均通过直连实现,取消了AS13000G6 的PCIe Switch设计,从而消除了数据链路上的瓶颈点。前端IO的性能及后端IO的理论性能均提升了4倍。
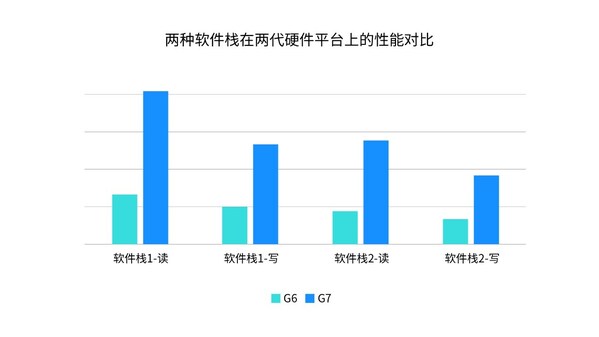
为测试性能表现,浪潮信息将两种软件栈分别部署在两代硬件上并进行读写测试。结果显示,与上一代硬件平台相比,在不同软件栈上AS13000G7的性能可提升170%-220%,有效保障了AI应用场景下的存储性能。
软硬协同
内核亲和力调度,内存访问效率提升4倍
在当前的AI基础设施平台中,计算服务器配置非常高,更高性能的CPU和更多的插槽数带来了NUMA(Non-Uniform Memory Access)节点数据的增加。在NUMA架构中,系统内存被划分为多个区域,每个区域属于一块特定的NUMA节点,每个节点都有自己的本地内存。因此,每个处理器访问本地内存的速度远快于访问其他节点内存的速度。
然而,在多核处理器环境下,会产生大量的跨NUMA远端访问。在分布式存储系统中,由于IO请求会经过用户态、内核态和远端存储集群,中间频繁的上下文切换会带来内存访问延迟。如下图,在未经过NUMA均衡的存储系统中,存储的缓存空间集中在单个NUMA节点内存内。当IO请求量增大时,所有其他NUMA节点的CPU核的数据访问均集中在单个Socket内,造成了大量跨Socket 、跨NUMA访问。这不仅导致了CPU核的超负荷运载和大量闲置,还使得不同Socket上的内存带宽严重不均衡,单次远端NUMA节点访问造成的微小时延累积将进一步增大整体时延,导致存储系统聚合带宽严重下降。
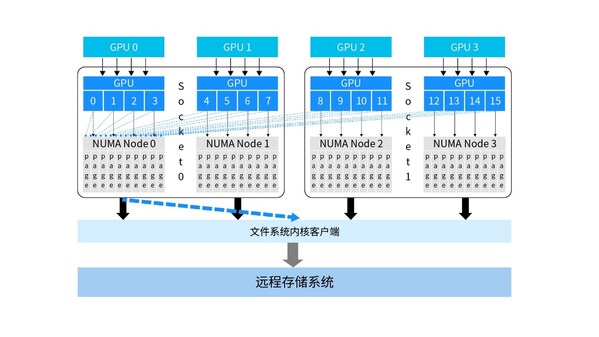
为了降低跨NUMA访问带来的时延,浪潮信息通过内核亲和力调度技术,在全新数控分离架构下,使内核客户端可自主控制数据页缓存分配策略并主动接管用户下发的IO任务。这种方式能够更加灵活地实现各类客户端内核态到远端存储池的数据移动策略。其中,针对不同的IO线程进行NUMA感知优化,将业务读线程与数据自动分配到相同的NUMA节点上,这样,所有数据均在本地NUMA内存命中,有效减少了高并发下NUMA节点间数据传输,降低了IO链路时延,4倍提升内存访问效率,保证负载均衡。
总体而言,进入到AI时代,存储性能关系到整个人工智能训练、推理和应用的效率。浪潮信息分布式存储平台AS13000G7软件优化、硬件升级和软硬协同三个优势,具备极致性能,成为AI时代各大用户的存储理想之选。
稿源:美通社





